
TL;DR:
- AI's role in fraud detection has become mission-critical, significantly outperforming traditional rule-based systems. Success depends on high-quality data, layered defenses, and explainability to build analyst trust and improve detection rates. Moving forward, combining advanced AI models with operational strategies is essential for effective financial fraud prevention.
The role of AI in fraud detection has shifted from experimental to mission-critical. Financial institutions now process billions of transactions monthly, and the threat surface expands every quarter. Yet despite the technology's measurable progress, a persistent gap exists between what AI actually delivers and what many leaders expect. AI-driven models reduce fraud losses by up to 50% and cut false alerts by as much as 60%. That is genuinely impressive. What this article covers goes further: how these models work, where they break down, what the data demands really look like, and what 2026's most capable organizations are doing differently.
Table of Contents
- Key takeaways
- The role of AI in fraud detection vs. traditional methods
- Why data quality determines AI outcomes
- Operational realities of deploying fraud AI
- Emerging AI capabilities shaping fraud detection in 2026
- My honest take on AI's fraud detection promise
- How Simplyai helps you operationalize fraud AI
- FAQ
Key takeaways
| Point | Details |
|---|---|
| AI outperforms rule-based systems | Machine learning models detect 2-4 times more fraud than traditional rule-based methods while reducing false positives. |
| Data quality drives model accuracy | Consistent, well-labeled fraud datasets matter more to model performance than architectural complexity. |
| Social engineering remains a blind spot | AI exceeds 99% accuracy on technical fraud but still misses roughly 40% of authorized payment scams. |
| Human oversight is non-negotiable | Explainability tools and human-in-the-loop review are what separate functional deployments from failed ones. |
| Layered defense delivers the best results | Combining AI with multifactor authentication, biometrics, and staff training produces the most durable fraud prevention outcomes. |
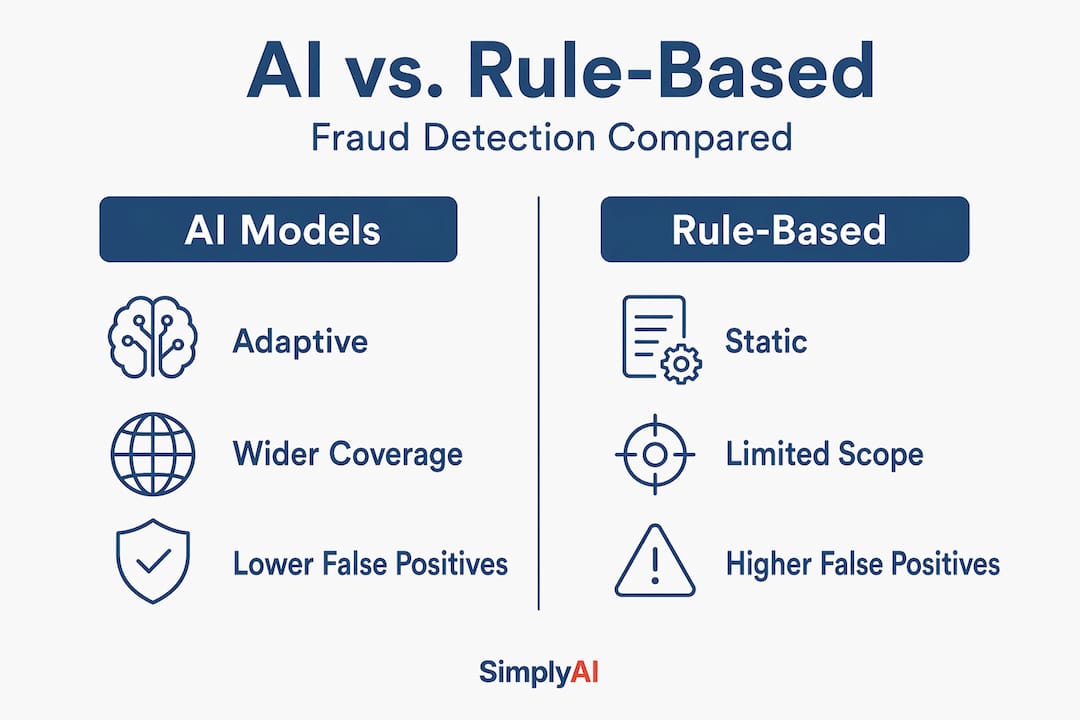
The role of AI in fraud detection vs. traditional methods
For most of the past two decades, fraud detection ran on static rule sets. If a transaction exceeded a threshold, came from an unfamiliar location, or matched a known fraud pattern, it triggered an alert. The logic was transparent and fast, but it aged poorly. Fraudsters learned the rules and worked around them. Legitimate customers were flagged constantly. Teams spent more time clearing false positives than catching actual fraud.
Machine learning fraud detection changed the calculus. Instead of matching transactions against fixed criteria, supervised learning models train on labeled historical data, learning which combinations of features correlate with confirmed fraud. Unsupervised models go further, identifying unusual clusters of behavior without needing pre-labeled fraud examples. Deep learning architectures process raw transaction attributes alongside behavioral signals, device fingerprints, and session metadata to generate risk scores with a granularity that no human analyst could replicate manually.
The performance gap is significant. AI models detect 2-4 times more fraud compared to rule-based approaches, while also producing far fewer false alerts. That reduction in false positives matters operationally. Every unnecessary alert costs analyst time, erodes customer trust, and can delay legitimate transactions.
| Approach | Detection breadth | False positive rate | Adaptability | Explainability |
|---|---|---|---|---|
| Rule-based systems | Narrow (known patterns only) | High | Static | High |
| Supervised ML models | Broad (known + novel patterns) | Low to medium | Retrain periodically | Moderate |
| Unsupervised ML models | Very broad (anomaly-based) | Medium | Continuous learning | Low to moderate |
| Deep learning models | Highest (behavioral + contextual) | Lowest | Adaptive | Low without added tools |
The practical insight from predictive analytics approaches is that rule-based systems and ML models are not mutually exclusive. The most effective architectures use rules to handle high-precision, well-understood threat categories, then layer machine learning on top to catch the rest.
Why data quality determines AI outcomes
Here is the uncomfortable truth that many AI vendors gloss over: a sophisticated model trained on messy data will perform worse than a simpler model trained on clean data. High-quality, consistent labeling is more critical to AI success than model complexity. That is not a minor footnote. It fundamentally shapes where teams should invest their time and budget.
Fraud datasets present specific challenges. Confirmed fraud cases are rare relative to legitimate transactions, sometimes representing less than 0.1% of total volume. This class imbalance means a naive model can achieve 99.9% accuracy simply by flagging nothing as fraud. Practitioners address this through techniques like synthetic minority oversampling (SMOTE), cost-sensitive learning, and precision-recall optimization rather than accuracy alone.
Noisy labels compound the problem. Disputed transactions are sometimes misclassified. Chargeback data arrives weeks after the fraud event, creating temporal lag in the training signal. Teams that do not account for this drift will find their models degrade over time, becoming confident about patterns that no longer reflect current fraud behavior.
The operational disciplines that separate high-performing fraud AI programs from struggling ones include:
- Regular retraining cycles tied to concept drift monitoring, using metrics like the Population Stability Index to detect when input distributions shift
- Dedicated data labeling workflows that route analyst-confirmed cases back into training pipelines quickly
- Segment-specific models rather than one global model, since fraud patterns in retail banking differ substantially from those in corporate payments
Pro Tip: Before evaluating a new AI model, audit your existing labeled dataset for labeling consistency across time periods. A six-month-old label assigned by a different team may reflect a different fraud definition than your current one. Inconsistency in labeling is the most common root cause of unexplained model underperformance.
Operational realities of deploying fraud AI
Deploying AI in financial fraud prevention is an organizational challenge as much as a technical one. AI fraud detection systems often remain centralized at senior management, with frontline analysts lacking the training to act on model outputs confidently. This creates a scenario where a model fires accurate alerts that go uninvestigated because the person receiving them does not understand what triggered it or how much to trust it.

Explainability tools address this directly. SHAP (SHapley Additive exPlanations) values decompose a model's prediction into the contribution of each feature, showing an analyst exactly why a specific transaction scored high risk. Large language models can go a step further, generating plain-English summaries of AI-generated alerts that describe the pattern in terms an analyst can act on immediately. Explainability is key to building analyst trust and avoiding the black-box confusion that paralyzes fraud teams.
Integration with legacy systems remains a stubborn barrier. Many financial institutions run core banking infrastructure built decades ago, and connecting modern AI models to those systems requires middleware, APIs, and careful data normalization work. Teams that skip this foundation often end up with AI operating in a silo, generating insights that cannot feed back into real-time decisioning.
Layered defense strategies combining AI with multifactor authentication, biometrics, and behavioral training provide the strongest protection. AI handles the pattern recognition and anomaly scoring. MFA and biometrics harden authentication. Employee training addresses the social engineering vectors that no algorithm can catch reliably.
That last point deserves emphasis. 40% of authorized payment scams still evade AI detection because they rely on manipulating legitimate users rather than exploiting technical vulnerabilities. When a customer is socially engineered into authorizing a transfer, the transaction looks entirely normal to a model scoring payment risk. Understanding the limits of AI-powered support in these contexts is critical for setting realistic expectations with stakeholders.
Pro Tip: When introducing AI fraud tools to analyst teams, run a structured communication program before go-live. Show analysts real examples of the model's reasoning, explain how escalation thresholds work, and create a feedback channel. Adoption rates and alert quality both improve significantly when analysts feel like partners in the system rather than users of a black box.
Emerging AI capabilities shaping fraud detection in 2026
The field is moving fast. Several developments that were experimental two years ago are now entering production deployments at institutions of all sizes.
Sequential deep learning models, particularly Long Short-Term Memory (LSTM) networks, analyze ordered sequences of transactions rather than evaluating each event in isolation. LSTM models detect transaction sequence patterns that single-event models miss entirely. A fraudster testing a stolen card with small purchases before a large withdrawal creates a temporal signature. LSTMs recognize it. Traditional models often do not.
Large language models are being integrated not just for explainability but for active fraud signal generation. By parsing unstructured data including customer service notes, complaint logs, and even social media signals, LLMs can surface fraud indicators that structured transaction data alone would miss. Data-driven analysis of unstructured fraud signals is an area where early adopters are seeing meaningful detection gains.
Generative AI plays a dual role. On the offensive side, it enables fraudsters to produce convincing phishing content, synthetic identities, and deepfake voice fraud at scale. On the defensive side, generative AI doubled detection rates of compromised cards while reducing false declines by 200% in documented bank deployments.
| AI capability | Primary fraud use case | Maturity in 2026 | Key limitation |
|---|---|---|---|
| Supervised ML (gradient boosting) | Transaction risk scoring | Production standard | Requires labeled data; static between retraining |
| Unsupervised anomaly detection | New fraud pattern discovery | Widely deployed | Higher false positive rate |
| LSTM / sequential deep learning | Behavioral sequence analysis | Growing adoption | Computationally intensive |
| LLM-generated alert explanations | Analyst decision support | Early majority | Accuracy depends on model grounding |
| Generative AI (defensive) | Synthetic fraud data generation | Emerging | Dual-use risk requires governance controls |
The direction of travel is clear: toward AI transparency, adaptive learning, and regulatory accountability. Regulators in the EU and US are increasingly scrutinizing automated decision-making in financial services, which means explainability is becoming a compliance requirement, not just a usability feature.
My honest take on AI's fraud detection promise
I have watched organizations spend aggressively on AI fraud tooling and see minimal returns. I have also seen leaner teams produce extraordinary results with simpler models. The difference almost always comes down to the same set of factors.
In my experience, the institutions that treat AI as a standalone fix are the ones that struggle most. They buy a sophisticated model, plug it into their transaction pipeline, and wait for fraud rates to drop. When results disappoint, they blame the technology. What they actually failed to do was invest in the data infrastructure, the analyst training, and the operational feedback loops that make any AI model perform.
What I have learned is that AI effectiveness increases dramatically as part of a multi-layered defense. That is not a hedging statement. It reflects a real architectural truth: AI is a detection engine, not a complete fraud prevention program. The teams winning in 2026 treat it exactly that way.
There is also an ethical dimension that does not get enough attention. Maintaining customer trust through transparency about AI usage is a genuine business obligation. Customers who receive a declined transaction or a fraud alert deserve a coherent explanation. When AI operates invisibly and gets it wrong, the damage to the customer relationship can outlast the fraud event itself.
My position is this: AI in fraud detection works, and it works well when deployed thoughtfully. But the organizations investing in data quality, analyst capability, and security culture alongside their AI platforms are the ones I consistently see outperforming the market.
— Theodor
How Simplyai helps you operationalize fraud AI
If the operational complexity described in this article feels familiar, you are not alone. Most organizations have the intent to deploy AI in fraud prevention but face real barriers in execution: fragmented data pipelines, undertrained staff, and AI tools that generate alerts no one fully understands.
Simplyai designs and implements AI automations for fraud workflows that address these gaps directly. From building clean, labeled data pipelines to deploying explainable ML models that integrate with existing case management systems, Simplyai's approach centers on operational results rather than technology for its own sake. The AI agents Simplyai deploys autonomously handle routine fraud investigation tasks, flagging high-risk cases for human review and documenting reasoning in plain language that any analyst can act on. For organizations at an earlier stage of the AI adoption curve, Simplyai also offers corporate AI education programs that build the internal capability fraud teams need to work effectively alongside AI systems. The goal is measurable fraud reduction, not a technology showcase.
FAQ
What is the role of AI in fraud detection?
AI analyzes transaction data, behavioral signals, and contextual features in real time to assign risk scores and flag suspicious activity. It detects 2-4 times more fraud than traditional rule-based systems while significantly reducing false positives.
How does machine learning fraud detection differ from rule-based systems?
Rule-based systems match transactions against fixed criteria, while machine learning models learn statistical patterns from historical data. ML adapts to evolving fraud tactics and catches novel schemes that static rules miss entirely.
Can AI detect all types of financial fraud?
No. AI exceeds 99% accuracy on technical fraud like account takeovers, but 40% of authorized payment scams evade detection because they exploit human behavior rather than technical vulnerabilities.
Why is data quality so critical to AI fraud models?
Consistent labeling and clean data matter more than model complexity because a sophisticated model trained on mislabeled or imbalanced data will produce unreliable risk scores regardless of its architectural sophistication.
What does a layered fraud defense strategy look like in practice?
It combines AI-driven transaction scoring with multifactor authentication, biometric verification, employee behavioral training, and human-in-the-loop escalation for high-risk alerts. No single layer is sufficient on its own.